| C# 初級講座 |
|
|
2022/10/23
この記事が対象とする製品・バージョン
|
|
Visual Studio 2022 | ◎ | 対象です。 |
|
|
Visual Studio 2019 | ◎ | 対象です。 |
|
|
Visual Studio 2017 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2015 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2013 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2012 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2010 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2008 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio 2005 | △ | 対象外ですが、参考になります。 |
|
|
Visual Studio.NET 2003 | × | 対象外です。 |
|
|
Visual Studio.NET (2002) | × | 対象外です。 |
| Visual Studio Code | △ | 対象外ですが、参考になります。 |
目次
forのいろいろな実例はこちらのサンプルでも公開しています。
今回は for の2回目です。 for ループを使ったプログラム例を見ながら for の理解を深めていきます。
for によるループはただぐるぐる繰り返すだけでなく、break(読み方:break=ブレイク)とcontinue(読み方:continue=コンティニュー)というキーワードを使って制御することができます。
for の中でbreakを使うとそのforは直ちに終了します。まだ回数が残っていても実行されません。
たとえば、次の for ループでは、終了条件が i <= 4 となっているので、 i が 4 のときに実行するのが最後ということになりますが、ループの中で if 文を使って i == 2 のときに break するようにしています。
for(int i = 0; i <= 4; i++)
{
System.Diagnostics.Debug.WriteLine($"{i}周目開始");
if (i == 2)
{
break;
}
System.Diagnostics.Debug.WriteLine($"{i}周目終了");
}
System.Diagnostics.Debug.WriteLine($"ループ終了");
結果として、i == 3 と i == 4 の周は実行されません。
実行すると次の通り出力されます。
0周目開始
0周目終了
1周目開始
1周目終了
2周目開始
ループ終了
「2周目開始」は出力されていますが、その後は「終了」は出力されず3周目、4周目も発生していないことがわかります。
break は for 以外に まだ初級講座では説明していないものも含めて foreach ・do ・while・ switch の構文でも同じような効果があるキーワードです。これらを組み合わせ使っている場合最も内側にある構造が制御対象になります。
continueはループ自体を終了させるのではなく、その周だけを終了させます。
次のプログラムは i == 2のときに continue しています。だから、 i == 2の周だけはここで終了します。
for(int i = 0; i <= 4; i++)
{
System.Diagnostics.Debug.WriteLine($"{i}周目開始");
if (i == 2)
{
continue;
}
System.Diagnostics.Debug.WriteLine($"{i}周目終了");
}
System.Diagnostics.Debug.WriteLine($"ループ終了");
これを実行すると次の通り出力されます。
0周目開始
0周目終了
1周目開始
1周目終了
2周目開始
3周目開始
3周目終了
4周目開始
4周目終了
ループ終了
2周目だけ、終了が出力されていない点がポイントです。
これで for の構文についてはすべて説明しました。ここからはいろいろな使い方を見ていって理解を深めましょう。
for の中に for を入れ子状に書いて2重ループにする使い方ができます。プログラムの世界では入れ子の構造のことを「ネスト」と呼びます。
次の例はかけ算の式と答えを出力します。
for(int i = 1; i <= 2; i++)
{
for(int j = 1; j <= 3; j++)
{
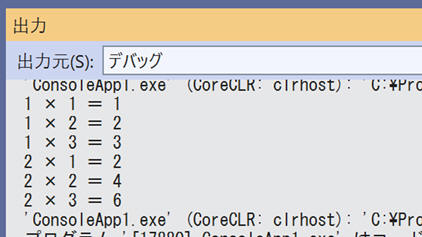
System.Diagnostics.Debug.WriteLine($"{i} × {j} = {i * j}");
}
}
この例では外側の for はカウンター変数が i で、内側は j であることに注意してください。x と y でも apple と banana でも良いですが、とにかく違う名前の変数にしておく必要があります。
このプログラムの実行結果は、Visual Studioの[デバッグ]メニューの[ウィンドウ]- [出力] で出力ウィンドウを表示して、出力元欄を「デバッグ」にすると表示できます。
この調子で for をどんどん増やして、3重、4重のループを記述することもできますが、まぁやめて置いた方が良いです。そのようなプログラムはとてもわかりにくくなりますし、あまり優れた構造ではありません。もし、どうしても多重ループにする必要を感じするならばループをそれぞれ別のメソッドとして定義するなどすれば、for の多重ループを割けることができるうえにプログラムの構造もすっきりします。
プロが作成するプログラムでもだいたい2重ループまでです。
このかけ算の例はわかりにくくはないので、このままでも良いのですが、今後の 参考のために、この2重ループのかけ算の例をメソッドを使って1重ループに書き換えたものを紹介しておきます。
ここではWindowsフォームアプリとして作ってみました。
namespace WinFormsApp1
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
for (int i = 1; i <= 2; i++)
{
CalcFor3Times(i);
}
}
private void CalcFor3Times(int i)
{
for(int j = 1; j <= 3; j++)
{
System.Diagnostics.Debug.WriteLine($"{i} × {j} = {i * j}");
}
}
}
}
2重ループを記述する代わりに2つの単一ループを記述してメソッドを分けています。こうすることで、多重ループを分割できます。ループが複雑になってしまう場合は、このやり方を思い出してください。
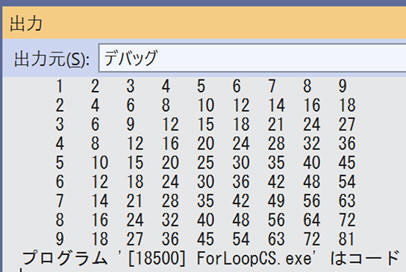
二重ループを使って簡単に九九の表を作ることができます。
for (int x = 1; x <= 9; x++)
{
for (int y = 1; y <= 9; y++)
{
System.Diagnostics.Debug.Write($"\t{x * y}");
}
System.Diagnostics.Debug.WriteLine("");
}
内側のforのループの中では WriteLine メソッドではなく、Writeメソッドを使っています。Writeメソッドで書き込んだ場合、改行しません。
だから、内側のループでは1行の中に9回計算結果を出力します。 \t はエスケープシーケンスを使って制御文字のタブを表しています。数字と数字の間にタブが出力されるというわけです。
そして、外側のループの最後の行で空の WriteLine メソッドを実行して改行だけ行っています。
この例を実行すると次のようになります。
配列と for は相性が抜群です。
配列については、初級講座第16回 直接で学ぶ配列 で説明していますが、忘れてしまっている人のために簡単に復習しておきましょう。
配列とは複数の変数をまとめるオブジェクトです。
たとえば、次のような3つの文字列の変数を使うプログラムを見てみましょう。
string value1 = "Apple";
string value2 = "Banana";
string value3 = "Cat";
System.Diagnostics.Debug.WriteLine(value1);
System.Diagnostics.Debug.WriteLine(value2);
System.Diagnostics.Debug.WriteLine(value3);
3つの文字列があるので変数も3つありばらばらです。
配列を使うとこれを1つにまとめることができます。たとえば、次の通りです。
string[] values = new string[3]; //この3は要素の数です。
values[0] = "Apple";
values[1] = "Banana";
values[2] = "Cat";
System.Diagnostics.Debug.WriteLine(values[0]);
System.Diagnostics.Debug.WriteLine(values[1]);
System.Diagnostics.Debug.WriteLine(values[2]);
変数は values 1つだけになりました。宣言時についている [] が配列の目印です。配列には複数の値が格納できるので個々の値を読み書きするときは、[0]、[1]、…のように「インデックス」または「添え字(そえじ)」と呼ばれる番号を付けています。
でも、配列を使った場合の方がプログラム量も多くなり、このままではあまり楽には見えません。
ちょっと改造してみましょう。
配列は { } を使って表現することができます。これを使うと初期値を設定するところが次のように楽になります。
string[] values = {"Apple", "Banana", "Cat"};
System.Diagnostics.Debug.WriteLine(values[0]);
System.Diagnostics.Debug.WriteLine(values[1]);
System.Diagnostics.Debug.WriteLine(values[2]);
いいですね。プログラム量が少なくなったし、わかりやすくなったような気がします。
インデックスを使って値を出力するところでいよいよ for ループの出番です。
string[] values = {"Apple", "Banana", "Cat"};
for (int i = 0; i < values.Length; i++)
{
System.Diagnostics.Debug.WriteLine(values[i]);
}
これで、配列の要素数が10個でも100個でもこのループだけで全部の値を出力することができます。
ポイントは2つあります。
1つは、i < values.Length としている部分です。values.Length は配列の要素の数を表します。この例だと配列の要素は "Apple", "Banana", "Cat" なので 3 です。こうすることで、配列の要素の数に応じてプログラムを書き換える必要はありません。
もう1つは、values[i] です。values[0] や values[1] のように数字を直接指定するのではなく、values[i] のように変数を使ってインデックスを指定することができます。この変数がforのカウンター変数と相性が良いのです。カウンター変数を指定しておくことで、自動的に1周目は0、2周目は1…のように順番に配列の要素にアクセスすることができます。
for ループと相性が良いのは、配列だけではありません。初級講座第17回 マウスでお絵描き では、配列のような使い方ができる List (リスト) を紹介しています。
List もインデックス(添え字)で要素にアクセスできるのでカウンター変数と組み合わせる使い方ができます。
List<string> values = new List<string>();
values.Add("Apple");
values.Add("Banana");
values.Add("Cat");
for (int i = 0; i < values.Count; i++)
{
System.Diagnostics.Debug.WriteLine(values[i]);
}
Listの場合は、要素の数を取得するのが Lengthプロパティではなく、Countプロパティです。
Listの場合も、{ } を使って、簡単に値を表現する方法があります。Listの場合は、コンストラクター呼び出しの直後に { } で値を列挙します。次の例では宣言時の型指定も var にして型推論にしてみました。
var values = new List<string>() { "Apple", "Banana","Cat"};
for (int i = 0; i < values.Count; i++)
{
System.Diagnostics.Debug.WriteLine(values[i]);
}
配列やListの他にも添え字でアクセスするものや、数字を順番に指定する機能については for と組み合わせる機会が多くなります。
また、次回取り上げる予定ですが foreach を使うともっと幅広い活用ができます。
ここからは For を使ったプログラム例を見てみましょう。
まずは、Unicode(ユニコード)で定義されているひらがなを抜き出してみます。
Unicode は文字コードの国際規格で、英語や漢字はもちろん、タイ語やフランス語、古代メソポタミアの楔型文字や、古代エジプトの象形文字、数学記号、絵文字など古今東西の文字を大量に収録しています。現在(2022年時点)では、最も標準的な文字コードです。
Unicodeは1つ1つの文字に「コードポイント」という番号を割り当てています。一般的に言われるところの文字コードですね。
ひらがなの場合、小さい「ぁ」が最初に定義されており、これのコードポイントは16進数で 3041 です。ここからコードポイント 309F までの連続する領域がひらがなです。
(本当は、3040も未割当のひらがな領域です。あと、明治時代以前によく使われていた変体仮名はこれとは別に定義されています。)
for を使って 16進数の3041 から 16進数の309F までの文字を取り出してみましょう。
C#のプログラムでは数値の先頭に 0x (ゼロと小文字のエックス)を付けることで16進数を表現できます。
for(int codePoint = 0x3041; codePoint <= 0x309F; codePoint++)
{
string moji = char.ConvertFromUtf32(codePoint);
System.Diagnostics.Debug.WriteLine($"{codePoint:X4} {moji}");
}
16進数を扱っていますが、for の動作は単純です、 変数 codePoint の初期値が 0x3041 で、そこから毎周+1して、0x309F以下である限りループを継続します。
Unicodeのコードポイントから文字を取得するには char構造体(読み方:char=キャラ)の ConvertFromUtf32メソッド(読み方:ConvertFromUtf32=コンバートフロムユーティーエフさんじゅうに)を使いました。文字は変数 moji に代入しています。
最後の Debug.WriteLine で出力している行は変数 codePoint と 変数 moji を出力しています。$ つきの 補間文字列では { } を使って変数を出力するときに : (コロン)で区切って書式を指定することができます。書式とは、たとえば、数値に3桁ごとにカンマを付けるとか、日付の年月日を / で区切る代わりに - で区切るとか、こういった表示方法の指定のことです。ここでは X4 という指定をしています。これは4桁の16進数という意味です。X が16進数、その後ろの4は4桁を表します。なお、小文字の x でも 16進数になります。16進数表記にしたときアルファベットを大文字にするのが X、小文字にするのが x です。
これを実行すると次のように表示されます。(これは抜粋です。)
3041 ぁ
3042 あ
3043 ぃ
3044 い
3045 ぅ
3046 う
3047 ぇ
3048 え
3049 ぉ
304A お
304B か
304C が
304D き
304E ぎ
途中3097と3098には文字が割り当てられいません。最後の文字 309F は「ゟ」という文字です。こんな平仮名あるんですね。「より」と読むようです。
サンプル通り Debug.WriteLine していれば出力ウィンドウのデバッグで「ゟ」を確認できます。コンソールアプリで Console.WriteLine などしていると、デフォルトのコンソール画面では使っているフォントにこの文字が週力されていないので ? になります。
縦にずらっと平仮名が出力されて、結果が見にくいので、16文字ずつ横に並べてみましょう。
キリが良いように開始は 0x3040 とします。
//1行目に 0 1 2 … E F を表示する。
System.Diagnostics.Debug.Write("\t\t");
for (int i = 0x0; i <= 0xF; i++)
{
System.Diagnostics.Debug.Write($"{i:X}\t");
}
System.Diagnostics.Debug.WriteLine("");
//2行目以降。外側の for は 1周で1行。baseCodePoint は 16ずつ増えていく。
for (int baseCodePoint = 0x3040; baseCodePoint <= 0x309F; baseCodePoint +=16)
{
System.Diagnostics.Debug.Write($"{baseCodePoint:X4}\t");
//この行に16文字出力する。
for (int pos = 0x0; pos <= 0xF; pos++)
{
int codePoint = baseCodePoint + pos;
string moji = char.ConvertFromUtf32(codePoint);
System.Diagnostics.Debug.Write($"{moji}\t");
}
System.Diagnostics.Debug.WriteLine(""); //改行。
}
文字の位置はタブで整えています。 文字列内で \t と記述するとタブになります。
実行すると、結果は次のようになります。
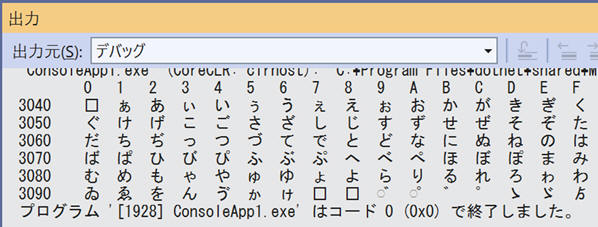
なかなか良いですね。
このプログラムは技術的には新しいものは出てきていないのですが、ちょっと複雑ですね。理解できますでしょうか。
2行目以降、文字を出力していく部分は二重ループになっています。外側の for は1周で1行です。
外側のループの1周目は 変数 baseCodePoint は 0x3040 です、
内側の for は 0x0 から 0xF まで繰り返すので、16文字出力します。 (16進数で0~Fとなると、0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F となるので 16 です。)
Debug.WriteLine ではなく、Debug.Write で書き込んでいるので、書き込んでも改行されません。
内側の for の1周目は 変数 pos が 0 なので、出力するコードポイント(codePoint)は baseCodePoint + pos で 0x3040 + 0x0 = 0x3040 になります。0x3040 には文字が割り当てられていません。
内側の for の2周目は 変数 pos が 1 なので、出力するコードポイント(codePoint)は baseCodePoint + pos で 0x3040 + 0x1 = 0x3041 になります。0x3041 の文字は「ぁ」です。1行目の2文字目にはちゃんと「ぁ」が出力されていますね。
このようにコードポイントを +1 しながら、タブ(\t)をはさんで16文字出力すると内側の for は終了です。その直後に空の Debug.WriteLine があるので改行だけ出力されます。
そして、外側の for の2周目に突入します。外側の for は baseCodePoint が 16ずつ増えるようになっています。
これを繰り返すことで上記のような出力になります。
ところで、for のカウンター変数はほとんどの場合 int で宣言しますが、型には特に制限はなく、long や byte はのもちろん、double や decimal のような小数や、日付を表すDateTime、文字列を表す string も使用できます。DateTime や string などを使う場合は、もちろん、i++ のようには書けないのでそれぞれの型に応じた書き方に変える必要はあります。もっともこれらはかなりトリッキーなので使うべきではありません。私は1度も見たことがありません。
ただ、文字コードを扱うプログラムでは、文字を表す char 型を使用するのは良いかもしれません。char型 は Unicode のコードポイントを表す型なので、今回の題材にはぴったりです。シングルクォーテーションを使って 'あ' と書くと「あ」のコードポイント 0x3042 を char 型で表していることになります。
char型は数値なので ++ などの計算もできます。
これを利用すると最初の単純なループは次のように書き換えられます。
for(char codePoint = 'ぁ'; codePoint <= 'ゟ'; codePoint++)
{
System.Diagnostics.Debug.WriteLine($"{(int)codePoint:X4} {codePoint}");
}
こんなプログラムは、ほとんどお目にかかることはないと思うので、こういう使い方もあるんだなぁくらいに眺めておいてもらえればOKです。
char型はそのまま出力すると文字としてい出力されて今うので、このプログラムでは数字として出力したいところで頭に (int) を付けています。これは「キャスト」と呼ばれる構文で、char型からint型に変換する意味になります。
文字コードのサンプルの最後に、ちょっとおかしなプログラムを紹介しましょう。
この1行のプログラムも上記と同じ動作をします。変数名 codePoint は短く cp にしてしまいました。
for (char cp = 'ぁ'; cp <= 'ゟ'; System.Diagnostics.Debug.WriteLine($"{(int)cp:X4} {cp++}"));
ループ本体は空です。空の場合は、1個のセミコロンが必要です。出力処理は for の 反復子セクションに書いてしまいました。反復子セクションは毎周実行されるのでループ本体の代わりに使用できる場合もあります。その中でインクリメント演算子 ++ を使って cp++ と記述しているので、 変数 cp は毎周 +1 されます。
このプログラムは for の理解を深める目的でちょっと書いてみるのはとても良いと思いますが、実践で使うプログラムには採用しないでくださいね。
だって、普通の for とだいぶ違うから、他の人がこのプログラムを見たら混乱してしまいます。実践のプログラムは誰が見てもわかる単純な機能が、シンプルに並んでいるのが一番良いのです。私のチームのプログラマーがこんなプログラムを書いたら私は書き直しを指示しますよ(笑いながら)。
毎月利息 1 % で 100万円を借りました。毎月2万円ずつ返すと、何か月で返済できるでしょうか?
つまり、最初の1か月目は利子がつい借金は 101万円になります。ここから2万円返済するので残高は 99万円です。
2か月目は99万円に利子1%が付くので、借金は99.99万円になります。ここから2万円返済するので残高は 97.99万円です。
さて、何か月で全部返済できるでしょうか。
| 月 | 1%の利子がついて | そこに2万円返済して |
|---|---|---|
| 1か月目 | 100万 × 1.01 = 101万円 | 99万円 |
| 2か月目 | 99万 × 1.01 = 99.99万円 | 97.99万円 |
| 3か月目 | 97.99万円 × 1.01 = 98.9699万円 | 96.9699万円 |
| … |
数学が得意な人は何やら数式で解いてしまうのかもしれませんが、私たちはプログラマーです。プログラムで解いてみましょう。
次のプログラムで答えがわかります。
decimal zandaka = 1000000; //借入100万円
decimal risoku = 0.01M; //利息1%
decimal hensai = 20000; //月々の返済額 2万円
for(int month = 1; month < 1000; month++)
{
//残高が1%増えます。
zandaka = zandaka * (1 + risoku);
//2万円返済します。
zandaka = zandaka - hensai;
System.Diagnostics.Debug.WriteLine($"{month}か月目 残高 {zandaka:0,0;'0'}円");
if (zandaka <= 0)
{
//残高がなければ返済完了
decimal total = month * hensai + zandaka; //総返済額
System.Diagnostics.Debug.WriteLine($"{month}か月で返済完了しました。総返済額 {total:0,0}円");
break;
}
}
if (zandaka > 0)
{
System.Diagnostics.Debug.WriteLine($"返済できませんでした;;");
}
このプログラムではforループを使って1000か月先まで残高を計算します。もし1000か月後にも返済が終わらないようなら、「返済できませんでした;;」と表示します。
このプログラムを実行すると次のように出力されます。
1か月目 残高 990,000円
2か月目 残高 979,900円
3か月目 残高 969,699円
4か月目 残高 959,396円
5か月目 残高 948,990円
6か月目 残高 938,480円
7か月目 残高 927,865円
…
68か月目 残高 32,778円
69か月目 残高 13,106円
70か月目 残高 0円
70か月で返済完了しました。総返済額
1,393,237円
返済まで6年近くかかり、借りた金額より約40万円も多く返済することになるのですね…。ボーナスなどで繰り上げ返済して総返済額を少なくしたくなってきます。
このプログラムのポイントを見てみましょう。
まず、 小数を扱う変数の型を decimal にしています。今回のように計算過程や結果に小数がでてくるお金をプログラムで扱う場合、型は必ず decimal 型にしてください。double や float でも小数を表現できますが、こちらは誤差が発生することがあるので、1円でもずれたら怒られる金額の計算に使うわけにはいきません。
最初に利息に設定している 0.01M の M はこの 0.01 が decimal型であることを示しています。この M を付けないでプログラム中に直接小数の値を記述すると double 型になります。今回は decimal型の変数 risoku を初期化したいので、値はdecimal型である必要があります。
返済が終わったかどうかは残高が 0以下かどうかで判断します。残高が0以下の場合は、それ以上計算する必要がないので break で for ループを終了します。
途中で出てくる書式付きの文字列 {zandaka:0,0;'0'} はちょっと複雑です。
これは zandaka がプラス(0より大きい)なら、それを3桁区切りのカンマ付きで出力し、残高がマイナスなら '0' と出力するという書式です。
少し分解して理解してみましょう。
書式「0,0」は数字を3桁区切りのカンマをつけて出力することを示しています。
たとえば、次のプログラムで実験してみましょう。
System.Diagnostics.Debug.WriteLine($"{123456789:0,0}");
このプログラムは、数値 123456789 に3桁ごとにカンマを付けて出力するので、「123,456,789」と出力されます。
{zandaka:0,0;'0'} の場合は、後にさらに ;'0' とあります。これの意味は「値がマイナスの場合は 0 と出力する」という意味です。
たとえば、次のプログラムは 値 1111 がプラスなので、普通に3桁区切りのカンマがついて「1,111」と出力されます。
System.Diagnostics.Debug.WriteLine($"{1111:0,0;'0'}");
しかし、次のプログラムは 値 -2222 がマイナスなので、「0」と出力されます。
System.Diagnostics.Debug.WriteLine($"{-2222:0,0;'0'}");
'0'の部分には、'A' でも、'どぼん' でも何でも好きなものを指定できます。
ということで {zandaka:0,0;'0'} は zandaka がまだあるなら、3桁区切りのカンマ付きで出力し、残高がマイナスなら '0' と出力することになります。
書式の記述は独特で慣れないととっつきにくいものを感じます。 for の ( ) の中よりもよっぽど複雑です。公式の説明はここにあります。難しいです…。
概要: .NET の数値、日付、列挙、その他の型の書式を設定する方法 | Microsoft Learn
for (int i = 1000; i <= 10000; i++)
{
//この if 文で i が素数であるか判定できます。
if (!Enumerable.Range(2, (int)Math.Sqrt(i)).Any((x) => i % x == 0))
{
System.Diagnostics.Debug.WriteLine($"見つかりました!それは {i} です。");
□;
}
}
for (□ c = 'ナ'; c <= 'ノ'; c++)
{
System.Diagnostics.Debug.Write(c);
}
System.Diagnostics.Debug.WriteLine("");
for (int i = 0; i < 300; i+=1)
{
System.Diagnostics.Debug.WriteLine($"10進数表記 {i} 16進数表記 {i:□}");
}
次の回は、foreach です。もう for にはうんざりしていますか? foreach の方が直感的で簡単ですよ。